A theory of images and visual culture, today, needs a theory of latent spaces. In a historical phase in which images are more and more generated, modified, circulated, seen and described by or with the help of different kinds of AI models, we need to understand the crucial role played by an abstract, mathematical construct whose cultural and political implications could hardly be overestimated. Latent spaces play a crucial role in generative AI models, from GANs to the recent diffusion models.
They also play a central role in the contemporary artistic practices that engage critically with AI, responding to its increasing presence in every aspect of culture, society, politics and economics. For a few years now, artists have developed different strategies to explore or modify the existing, dominant latent spaces, or to produce their own alternative, antagonist, counter-hegemonic ones. Considered together, these different strategies show the awareness with which the field of contemporary art is tackling the presence and the agency of this hidden layer of mathematical abstraction that participates in the shaping of cultural and political imaginaries.
Read full transcript (generated by Whisper)
Thank you very much. Okay, so first of all, huge thanks to Hito and Francis for this invitation. And yeah, my talk is entitled Politics of Latent Spaces. And as you have already seen with Gregory, we have an ongoing dialogue that's been going on now for some years. So you will hear some moments of convergence between what he said and what I'm saying, but also differences given also the different points of view from which we speak. And I'd like to frame this presentation in relation to the exhibition that I just curated at the Jeunesse. Jeu de Poem, entitled Le Monde Selon L'IA, The World Through AI, is the English title. Because in many ways, this is an exhibition about art in the age of average and of the new AI authoritarians. When I read the presentation of this event that's published on the website and the list of questions that Francis and Hito have launched, as a starting point, as a starting platform, I really found in these questions an echo of the same questions that I was asking myself together in dialogue with the artists who participated in the exhibition in conceiving this exhibition at the Jeu de Poem.
It's an exhibition that comes with a catalogue, both in English and in French. The catalogue is almost at the same time a catalogue and a book. It contains a number of books. It contains a number of essays by various scholars like Kate Crawford, Noam Elcott, Fabienne Offert, and others. And the exhibition is organized along the two floors of the Jeu de Poem with the structure that you see here, which is not at all a kind of a structured, an articulation of sections that we apply the top down, before placing the works in them. But it's a structure, an articulation that they're really, and I think, is the most important thing. came from intense engagement and discussions with the artists that were participating. At the ground floor, which is where the exhibition begins, we begin with a section titled Materials, with a series of works that underline the profound material, even geological dimension of digital systems, including AI models, countering the whole discourse about the digital and AI being a form of dematerialization, a discourse that is famously promoted by metaphors such as the one of the cloud. There's a section on collective intelligence, which establishes connections between AI as a form of collective intelligence and other forms of collective intelligence happening in the biological and in the animal domains.
There's a section on cartographies, of AI in space and time. It is here that we have two famous diagrams by Kate Crawford and Vladan Joller, Anatomy of an AI System and Calculating Empires. And then there's two sections that deal with the domain of so-called analytic AI, meaning AI systems whose main purpose is to detect, recognize, and classify. We have a section on machine vision, a section on face and emotional recognition, and a section on AI. And then we have a section on AI, and a section on face and emotional recognition, and a section on AI, and a section on micro-labor. These millions of workers, Turkers, as they are sometimes called, located mostly in the global south, but not only, who contribute to the training and to the moderating of AI systems. The whole first floor, instead, is dedicated to generative AI, to works that have been realized with the different generative AI systems. And we have a series of projects that are being done in the global south, which are being developed in the global south, and we are working on the development of the new generative AI models, beginning with the GANs, Generative Adversarial Networks, in the mid-2010s, and arriving to the recent diffusion models.
The entire exhibition, in a way, is about seeing how artists have reacted during the last 10 years to the increasing presence of AI models and algorithms across all layers of culture, society, and society. And we have a series of projects that have been developed that are being developed in a very different way and that are really important to the global society, economics, politics, of course. And the idea was also to privilege artworks that had a kind of a critical reflective dimension that were not at all only into the exploration of these tools, but actually in thinking about their profound economic and social implications. And we're very, very glad and honored to have a new installation by Hito Steyl, entitled Mechanical Kurds, which is a project that we're working on at the moment. And it's a project that we're working on which has the dispositif of presentation that you see here, and also a large new installation that you have already seen by Gregory Chytomsky, entitled The Fourth Memory. Another particularity of the exhibition is the presence of a series of time capsules, vitrines in which we have positioned a whole series of objects, devices, photographs, artworks that are meant to give a kind of media archeological perspective to these recent transformations.
So that on certain topics, such as, for example, the relations between the current face and the motion of recognition systems, we show how they have their roots in the longer history, such as the history of physiognomics, dating back to at least the 17th century, and then of course going through the 19th century with the rise of social, criminal, and racial physiognomics. There's also a time capsule on trying to locate the recent development of machine vision systems in the longer history of attempts to automatize visual perceptions. For example, also in the 1920s and 30s and 40s with filmmakers and theorists, such as Tsigal-Verto, Jean Epstein, who in very different social and political context, reflected on what it meant to see the world through the mechanical eye of the camera, through what Tsigal-Verto called the kino glass, and Jean Epstein called a servo metallic, a metallic brain, an idea that he will develop then in 1946 in a book called The Intelligence of a Machine, in which the intelligence machine was cinema as a robot, as he called it, endowed with the ability, as he called it, endowed with the ability, to be endowed with its own categories, its own understanding of time and space and on the visible world.
So throughout the exhibition, a concept that is central and on which I wrote the text that is published in the catalog is the concept of latent space. And the idea was really to reflect on this notion, on this entity as both a site of artistic production and political action. In working on this concept, I always like to remind also the way in which Hito described her role in the credits of one of her recent installations, one of her recent videos, Animal Spirits, a long list of tasks that Hito, you did in preparing this work. You at some point, you mentioned also including, you say, all AI processes, including the extremely boring ones, latent space architecture and path making. The idea that as an artist working with latent spaces is also being engaged as much as possible with the construction of its architecture and the tracing of paths of the trajectories within it. So what I'm going to present to you now is a reflection on this notion, on this entity, which begins by really realizing the fact that, much as we should stop speaking about AI as a singular, as a single block, and really paying attention to the various different models and algorithms that are used in this field.
In the same way we should not speak about the latent space. We should really always speak about latent spaces in the plural because the situation we are currently in is one of competing, conflictual, latent spaces. There is a latent space for each trained AI model and for each version of each trained AI model. And I think it's really important to keep in mind this plurality because it is also in this plurality, as we will see, that lines of possible political actions can be found. So I'll begin with the first section entitled Latent Spaces and Visual Culture, which basically starts from the presupposition that, as we read here, a theory of images and visual culture today needs a theory of latent spaces. In a historical phase in which AI models intervene more and more in the ways in which images are captured, generated, modified, seen, and described, we need to understand the crucial role played by an abstract. An abstract mathematical construct whose political implications could hardly be overestimated. Latent space, here I will give another definition, but Gregory already provided ones, is a technical term, but a term with very important metaphorical connotations connected to the idea of latency.
And it's a foundational concept in machine learning and so-called artificial intelligence. It refers to the abstract mathematical space within which the vastness… The vastness, what do you mean by Latent spaces are made of vectors. Something, of course, which is very clear now, which Dr. Grigori has presented. There are many different mathematical operations in this! When if you look at complex and complex and complex objects in a periodic pattern, there are many different Scoogi differences. When things from the Daariein and Mordani SQL worldיף therein require permutable domain-system penetration. Where components come together. Where models exist as part of a magic API and are reg sinoледur be. And in addition there are basal and floating broadly infinitesimalOOD valuesいて MUSIC a 방식 law to form an queue so thatadia 당신iemi And then come on to Ggie Gregg's explanation of our ability to interpret data betweenэопросm Proposal and Ãdiä Kerry Murphy. Gregory's presentation. And vectors basically look like this, even though there's many ways to visualize them. They are lists of numbers arranged in specific order and these numbers capture coordinates. Coordinates of data points that have been embedded in latent space. Here you have a 100 dimensional vectors but in the latent spaces of the current AI models vectors can have hundreds or even thousands of dimensions. Now latent spaces are now present across the entire spectrum of AI models and applications of AI models. We find them in the neural networks that are used for machine vision applications. We find them in the systems used for face and the motion.
So the methods that are used to measure the size of the devices are the systems used for the of recognition, we find them in all the AI models for image generation and modification, and we find them also in recommendation systems. If we look at the main neural networks that have been at the center of this vast impact of AI technologies on images since the beginning of the 2010s, we see that different kinds of latent spaces are present in each one of them. We find them in the convolutional neural networks which at the beginning of the 2010s contributed to the increased performances of machine vision systems. We find them in variational autoencoders invented in 2013. We find them in generative adversarial networks. We find them in CLIP . This key model which embeds in a common latent space both words and images and allows is the kind of fundamental break for all the so-called multi-modal AI systems. And we also find them in the recent diffusion models. This is a very kind of schematic attempt to describe how stable diffusion works. And you can see that both, let's see if I can find, yeah. PTBC. We have eruption of the data the overall signal ratios, and trickles and ideaойд.
If you look here, from this néal static program, you can see both the prompts are encoded by a CLIP encoder within tokens and embedded in a latent space, and this embedding in this CLIP latent space steers the denoising process that happens through different passages of the so-called U-net, in which images themselves are also encoded in latent spaces. So it's as if the textual latent space that was to have this tone long called same thing, closely circling from the prophylactic current or pineuitic hadhal natural concordance and brought onto the latent space. It's not as if the spectrum lawn isn't quite so long-term. And so there you see that the user therefore can see the so-called pakai steers the diffusion in order to then finally come to the image decoder that leads to the image, the final outcome. So that kind of crucial process of denoising that happens in diffusion models, of which sable diffusion is of course one of them, is steered by the latent space of a clip. Now all these different latent spaces share a series of key epistemological properties which are also in many ways ideological properties. To begin with they are all forms of compression. They are forms of compression which is not like the compression that is used, for example to compress single files such as mp3, mp4, jpeg, they are a form of compression which is toolcasting.
And for this it is also extremely difficult for real mice to know exactly which features lays why so much 어�uder click is contained in their own separation. compression that actually compresses entire swaths of digital cultural objects into latent space or representations that capture not only the features of the single objects but also certain relations between these objects. Certain rather than others. So there's an implicit choice of which features are preserved that happens according to kind of often obscure and very difficult to decipher logic. But two colleagues, two scholars whose work I appreciate a lot, Leonardo Impet and Fabian Offert, talk about the kind of lossy compression that is done by latent spaces as a form of epistemic compression. A compression of knowledge that allows not only for the individual to be able to express the information but also to express the information. So the idea is that the data is not only for the representation of existing data but also for the production of new data. Meaning that once all these cultural objects are compressed into latent spaces and turn into vectors, you can always try to go and find vectors between vectors, data points between data points. Another interesting feature of latent space is the fact that there are spaces of media transformation.
Spaces of, again quoting Impet and Offert, spaces of media collapse. Why? Because objects that exist in digital forms but manifest themselves in different media such as texts, images, sounds, voices and so on, are all collapsed within one meta medium, which is vectors, and once they are processed within those vectors, they can re-emerge out of latent space in different media forms. So, in this case, we have a very interesting idea of what latent space is. So latent space is a space of media transformation, a space also of intermediality, we could say, and this intermediality is made possible by a kind of flattening, a collapse into the one medium of vectors. Latent spaces also are part of a large process of vectorization of culture that Gregory has already pointed out. They potentially turn every single cultural object into a vector. And so, in this case, we have a very interesting idea of the object that exists in digital form, that is, of course, the precondition. They turn it into vectors, and by being turned into vectors, these objects are positioned, processed, but also oriented. This is also a very important point that Gregory mentioned. Vectors have an orientation. And latent spaces also have orientations. They have tendencies.
They have currents, in a way, using a metaphorical term. They tend to lead in certain directions rather than others. And a possible site of political action, as we will see, is really about somehow countering these inherent currents, establishing new directions, reorganizing the flows within latent spaces. Latent spaces also are playing more and more a key role in the process of… … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … much about this concept now, but how do we position it in history? Is it something that appeared with the generative AI models or with the convolutional neural networks, or is something that we can place in history? And if we do, how do we place it? Now, various studies in very recent times have found different possible sources of this notion. In the history of vector arithmetics, going back to the 19th century, in the history of statistics and principal component analysis at the beginning of the 20th, in the history of psychometrics, of the measure of intelligence, in the history of neurobiology, or even the history of library information retrieval.
But what I find particularly interesting from my point of view as a researcher in the field of media studies is to think about them in terms of the history of the world. And I think that's cultural techniques, kulturtechniken. Think about them in relation to cultural techniques of compression, projection, positioning, organizing. Conceived in these ways, a long history of latent spaces, which of course would be written retroactively from the point of view of the current AI models, could include all those techniques and forms of representation that reduce the number of dimensions of the objects that are in the world. And I think that's something we could use to help us understand the types of phenomena that they represent in order to position them in a new space, and perform on them or with them different kinds of operation. Interpreted in this way, we could say that latent spaces have something in common with maps as forms of representation through dimensionality reduction. We can also say that they have something in common with the perspectival representation, with different kinds of projection, including perspectival representation. And I'm not saying at all that there is a full analogy between the two, but I'm just thinking that perhaps thinking of latent spaces in relation to perspective may help us understanding something about latent spaces and something about perspective.
For example, thinking about them in relation to perspective with me asks the question of whether latent spaces have a point of view, of where latent spaces are the expression of a certain situated position, a certain situated knowledge, or are they kind of purely abstract vector and we already heard that latent spaces have directions, orientations, and we could add to our reflection the question of the point of view. Latent spaces also have analogies with the history of grid based systems of representation as cultural techniques. I'm thinking here of the book by Bernard Ziegert. It's called The Greatest Rhymes. The Greatest Rhymes is a work by a huge… cultural techniques, grids, filters, doors, systems of representation that assign specific orthogonal coordinates of what they represent. And we know that in latent spaces also the objects that are encoded and embedded into them are represented through coordinates, except that we're talking about hundreds or thousands of coordinates. Finally, it may be interesting to think of latent spaces in relation to institutions such as libraries and archives. Keeping in mind, of course, some crucial differences to which I will come in a second. For those of you who have seen it, there's a fantastic film by Alain Resnais entitled Toute la mémoire du monde, All the World's Memory from 1956, which is a film about the National Library in Paris, the Bibliothèque Nationale.
And it's like a 30-minute long trailer. It's a trajectory across this sort of organism in which we do see all the processes of collecting knowledge in book, journal, magazine forms, indexing, ordering, positioning, retrieving, distributing, circulating. It's really almost a film about the National Library in terms of cultural techniques. And once all these systems of… collecting, positioning, indexing is done and circulation begins, then another moment comes, which is the one of the processing of all this knowledge that has been catalogized, organized, positioned. And this, of course, has very interesting analogies with latent spaces as ways of encoding, positioning, and processing different cultural objects, stored on the internet. There's, though, a very, very important and fundamental distinction between libraries and archives and latent spaces, which is that whereas libraries and archives were meant traditionally not only to store, position, collect, organize, but also to retrieve, to find the objects that were positioned in them, latent spaces are spaces for transformation and not for retrieval. Once a cultural object… has been compressed into a latent space of representation, into this vast, huge system of vectors, you do not find it again as it is. You find endless variations of them.
So latent spaces are spaces for transformation rather than retrieval. Another huge difference with most libraries and archives, but not all of them, is that latent spaces are not accessible. Latent spaces are… are mostly invisible and inaccessible. Gregory was able, indeed, a few days ago, to show me that specific checkpoint on stable diffusion that he had saved on his computer and tell me, here is a latent space. But that is a very specific and quite a rare case because, actually, the latent spaces of the proprietary private closed models, such as Midjourney, such as ChachiPT, such as Gemini and so on, they are not accessible in any way. In a way, the only way to visualize a tiny, tiny, tiny, tiny portion of them is by generating images out of them or texts. That's the only possibility. So all these epistemological and genealogical properties of latent spaces obviously influence their political status, their political dimension, on which I'd like to say, now, that I'm going to talk about. I'm going to say now something. These operations of compression, vectorization, embedding, all have a political dimension because they are massive. When you think that, as Gregory reminded me again in our conversations recently, that one downloaded version of stable diffusion has a weight of about six gigabytes, and in that version, in that latent space, have been encoded and vectorized the five billion connected texted images of the LION5B training set, you can only try to imagine the rate of compression that has happened.
And you told me that it was something like 99.9, meaning that the compression is absolutely huge. And this compression, which is a form of mathematization, is a flattening, it's an erasure of context because enormous aspects of those cultural objects get lost in this transformation to vectors. This flattening, mathematization, erasure is something that has a profound political dimension. Second point is that latent spaces, as I already said, are mostly invisible and unimaginable. For structural reasons, because we have, you know, we have a very hard time imagining a space that has more than three dimensions, we can try to add a time as the fourth, but certainly we cannot imagine in any way a space with hundreds or thousands of dimensions, even though those hundreds or thousands of dimensions are actually an extreme form of compression compared to the size of the training set. And just to give an example, if you take an image, a single image with 4K resolution, and you wanted to describe it with a vector that captures each single pixel with its coordinates and color values, you would have to use 25 million numbers to describe one image. So the fact of reducing that image to a vector of hundreds or maybe a few thousands of dimensions is already a huge form of compression.
So there are some techniques to try to visualize latent spaces. Such as the famous T-SNE. But they are, of course, very, very partial. They are bidimensional. In general, latent spaces are exactly the example of that black boxing of AI technologies. Considered in their totality, latent spaces therefore remain radically invisible and inaccessible. They are not meant to be perceivable by humans, but rather operational. They are not meant to be rationalized by algorithms and AI models. Now, another political dimension of latent spaces is the fact that, as I said before, we are now in a moment, in a historical phase, in which there are several, many different competing latent spaces. Some of them are proprietary and closed. Others, instead, are released in open source and can be at least partially modified. So if we look at this list, which is only partial, only the two in yellow are open source latent models that you can actually work with. In the case of stable diffusion, even downloaded and intervening on it through different forms of fine-tuning, such as LORAS and others. And what is crucially important is that, at the present moment, there is no unified latent space of culture.
There is a kind of common process of vectorization. There's a number of dominant deep learning architectures that are producing this, but there's not common latent space of culture. There's no way to create a sort of translation from the latent space of mid-journey to the latent space of stable diffusion to the latent space of gemini. Each of them is a system on its own. And what happens, and here is another point, is that in the case of the private space, in the case of the private and closed models, latent spaces are not at all spaces of infinite generativity, spaces that can be explored in all directions. Actually, these latent spaces are subject to different imperatives, such as the one of so-called alignment. They, for example, tend to orientate direct image generations towards the imperative of photorealism, towards certain dominant styles. And then there's all sorts of forms of censorship. There's band prompts, there's shadow prompts, there's images that you will never be able to actually visualize. And all of this alignment, censorship, happens completely outside of our control. Models released in open source instead can be downloaded, appropriated, modified, at least in part, through different forms of fine-tuning.
All this shows that what we find at the present moment is a series of models that exert, and latent spaces, that exert a profound influence on the distinction between what can be visualized and what remains invisible, between the visible and the sayable, because among the major transformations that are happening, there's also this kind of algorithmic reorganization of the relationships between words and images. And also latent spaces intervene in the distinction between noise and signal, between formless and form. As I said, it is, in the case of stable diffusion, it is CLIP, the model CLIP, that steers the denoising and makes sure that the denoising is aligned with the way in which CLIP has understood the words of the prompt. In some cases, these latent spaces also present themselves with a real kind of totalitarian dimension. I found it extremely interesting and bizarre to read in 2022 when stable diffusion was publicly released that the way it was presented by stability AI was, as you can read up there, as the culmination of many hours of collective effort to create a single file that compresses the visual information of humanity into a few gigabytes. The visual information of humanity.
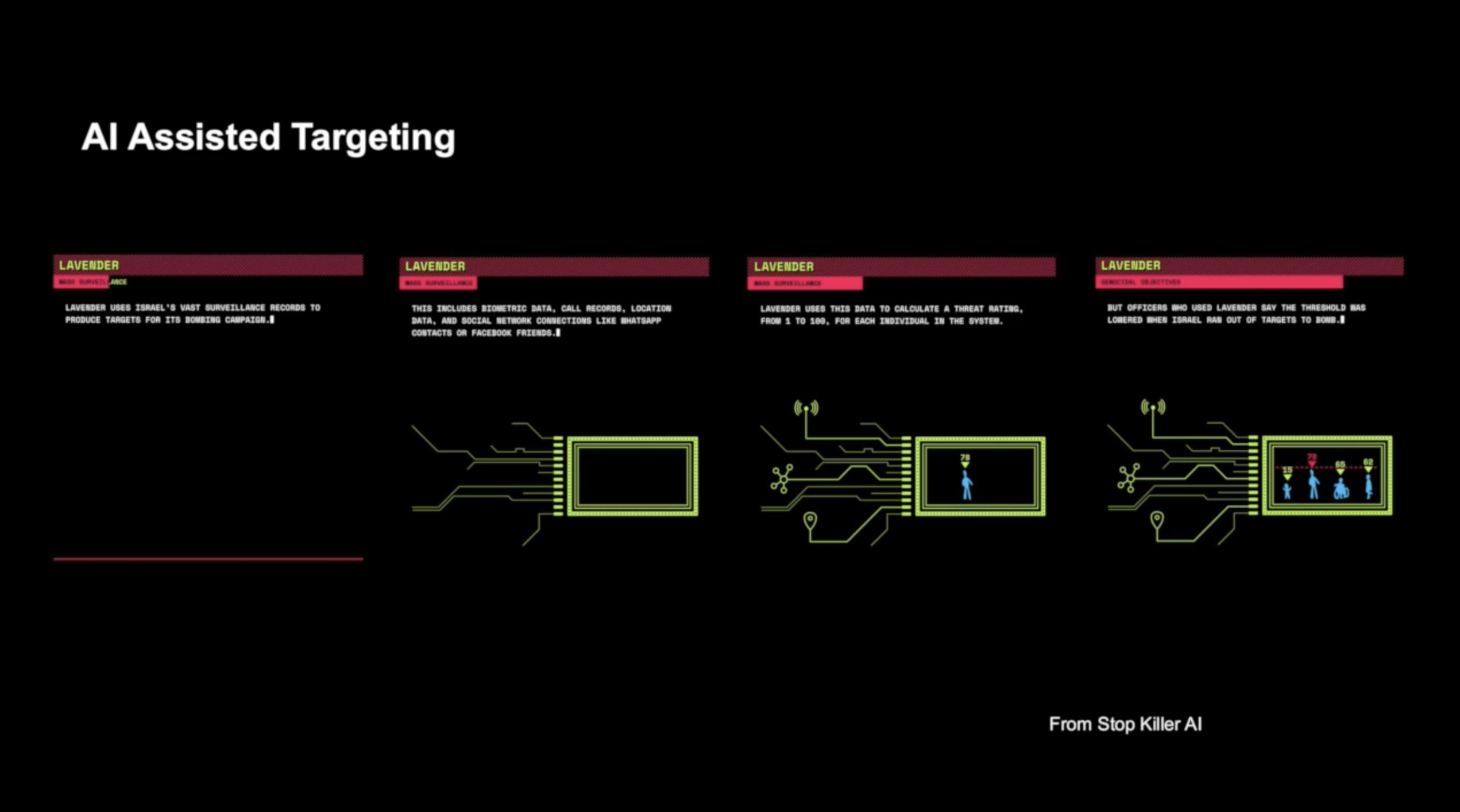
And by the way, Gregory, I wonder if this image of utter destruction and fire lies somehow behind those images that you showed us from your installation. Now, as we know now, thanks to this very important study that I highly recommend by Christo Bushek and Yair Thorp, models all the way down, what LION5B contains is not at all the entire visual history of humanity. It's as large as it is, with five billion images and texts. A lot of these images actually come from online shopping sites such as Shopify. There's massive quantities of stock images. There's a whole series of decisions, including the creation of the infamous subset called LION Aesthetics, which direct the generation of images in certain directions rather than others. If you open Lexica, which is one of the portals to access stable diffusion, you will find that these are the kinds of images that are suggested as the ones that the model kind of generates by default. And this is where, of course, the far right is really going in, you know, generating all these nauseating images that we've seen, in recent times, including this one stemming from the popularization of the so-called Ghibli style with Chachapiti.
So in many ways, AI Slop is basically about using these models and following their default directions, their default vector orientations. Now, faced with all this, the question is, how have artists reacted to this? And part of the work that I did in the exhibition, and I worked also with three associate curators that I'd like to remind, Ada Kerman, Alexandre Geffen, and Pia Vueing, was to really kind of explore the field of contemporary artists working critically with these models to see what kind of strategies they could use to create these images. And I think that's really important. What kind of strategies they had found to position themselves in relation to these different latent spaces. And I could identify a number of approaches that I could sum up here. One is about producing different autonomous, smaller latent spaces. Not use the ones that are provided by the mainstream dominant hegemonic AI companies, but try to work on smaller, more malleable latent spaces. Second one is about working with the large models, but focus on the open source ones and adopt different approaches, different techniques of so-called fine tuning in order to intervene somehow in the vector ontology of the latent spaces and introduce new entities, new directions, new properties.
A third approach is about using the dominant latent spaces without really doing any kind of fine tuning, but trying to use prompts in order to explore remote areas of these spaces. Then there's one which is about finding ways to influence future latent spaces, and I will show you in a moment. It's actually by one of the artists that will speak tomorrow. And a fifth is, I call it, visualizing the inner counterintuitive logics of latent spaces. So let me give you just some brief examples for each approach. If I think of the first one, one of the examples that comes to mind is of course Trevor Paglen's adversarially evolved hallucinations. These series of images generated with GANs after training GANs with a series of absolutely non-standard training sets, training sets that are not made of images that are somehow very similar in their coherence in terms of representing the same objects, human faces, apples, and so on and so on. But data sets that are much more complex and that often include images that have profound and deep cultural symbolic dimensions. If we look at this list, these are all the data sets that Trevor Paglen put together by searching for images from various sources, and we focused on the way that he would interpret the images.
For example, on the one called The Interpretation of Dreams, this was a data set collecting images that represent objects or places mentioned in Sigmund Freud's book. And out of this latest set, he trains a GAN, locally trained, and then chooses one of the generated images as the artwork. Working with the data set entitled Monsters of Capitalism, including vampires, zombies, and so on, figures that at some point in history, as it happens in Marx's first book of Capital, for the figure of the vampire, figures that have been associated with capitalism, he trained a GAN and generated this image. But I think that this approach, Hito, you will correct me if I'm wrong, is also in a way the one that you adopted when you worked with GANs in installations such as Power Plants, This is the Future, Social Sim, and Animal Spirits. These are moments in which you worked with GANs and you directly intervened, as we said before, in as much as possible, because it's never a full, complete intervention, but play a role, play an important agency in shaping the architecture and tracing paths within latent space. Now, another project that is being developed currently is by Hollyoak, by Herndon and Matt Dryhurst, and I don't know if Matt has already joined us or if he will come tomorrow, but it's a project for a new generative AI model called Public Diffusion, which is being trained with a data set of 12 million images called Public Domain, and these are images free of copyright or freely, voluntarily given by artists who accept to participate in the project and are then given revenues from this participation.
So this is also a very interesting attempt to create alternative latent spaces to the ones that are currently hegemonic. Now, fine-tuning open source models, this is exactly what Gregory does. You work with lawyers, you introduce entities in latent spaces, you create a series of prompts to, as you say, create worlds, generate images that share a sort of atmospheric ontological common aspects, and this is, I really invite you, if you can come to Paris, to see this installation. Working with prompts and using common models but trying to find remote areas in their latent spaces is what we find in the exhibition, for example, in the work by Eric Bulot, who is both a filmmaker who was not using at all AI until a couple of years ago. He's been very much interested in the history of what he calls cinéma imaginaire, which is a cinema that can be found in unrealized film projects or in ideas of cinema or cinematic dispositives that can be found across the history of literature, for example, in the writings of Raymond Roussel, and what Eric Bulot did in this case was to start from a series of notes from a symbolist writer from the 1920s and 30s in France called Saint-Paul Roux.
The notes are called Cinéma Vivant, Living Cinema, and they describe a kind of hypothetical, utopian future cinema in which the sky becomes the projection surface and images have a kind of crystalline, three-dimensional dimension, and he generated this series of images that somehow give some visual presence to these ideas. So, in a way, he's treating, as he says, generative AI models as speculative archives in which you can go and search for ideas, for visual possibilities that never really materialized. The idea of trying to influence future latent spaces is also extremely interesting, and this is at the center of this project by, again, Holly Herndon and Matt Dreihurst. The project is entitled Harry Mutant X. It was presented at the 2024 Whitney Biennial and then again in our exhibition. And what they did is to try to understand how the latent space of stable diffusion had encoded in vectors the image of Holly Herndon, a musician who has an extensive Internet presence and therefore enough images of her to have a presence in latent space. And after finding, through a technique called textual inversion, that the vectors representing her had mostly focused on her red hair and her braids, they decided to create a costume in which she looks kind of like a golem figure with this exaggerated feature.
And they launched an operation that they call cliché poisoning, meaning trying to find ways to inject into the Internet images that amplify this cliché, hoping that in the future they will end up in future training sets, thereby influencing future latent spaces. They created a text-to-image model that you could access through a QR code, and whatever prompt you wrote, you would generate images that look like this, that are endless variations of this clichéd Holly Herndon. So these are some of the strategies that I found in preparing this exhibition. And many of them share, in many cases, the idea of working with latent spaces as, I would say, meta-archives. As meta-archives in which huge quantities of cultural objects taken from the Internet, from specific areas of the Internet, have been embedded, vectorized, and positioned, and out of which other possible images may emerge. And these possible images, I often like to refer to this book, just published by Alexander Kluge, living here in Munich, Der Konjunktiv, Der Bilder. He talks of these generated images as images that exist in the grammatical mood of our sense of what is possible, the specific modality of images used to visualize hypotheticals and heterotopias.
And I think that it's perhaps in exploring this Konjunktiv that lies as one of the possible political strategies that we may adopt in this landscape. Strategies that I think should try to avoid as much as possible using the energy-hungry, platform-based, hegemonic latent spaces to instead privilege open-source, directly accessible, modifiable, malleable latent spaces in order to explore this kind of conjuncting or subjunctive of images. So thank you very much again. Thank you. Thank you so much, Antonio, for this brilliant lecture. I'm sure we have some immediate questions. Yes. The microphone is coming. Thank you for the great talks. I wanted to ask about the aspect of, the unnerving aspect of compression, because there seems to be something like politically interesting there, but could you comment a bit more on that? Because to me it seems like compression always happens when you kind of take a continuous experience of an artwork, for example, and you write it down into a discrete text or when you categorize it. So it seems that we also do that, and also as artists we do that a lot. So, yeah. Yeah, you're totally right. Compression in itself is an extremely common cognitive, perceptual, even perhaps ontological phenomenon.
The question is, of course, what kind of compression? And already in the compression, that is at the basis of formats such as JPEGs or MP3, there was an ideology embedded. The idea that you could reduce the size of certain cultural objects, an image, a sound, a piece of music, by focusing only on those aspects that can be perceived by a human subject in certain conditions, at a certain distance, and so on. So there was, it was not a neutral compression. It was a compression that had already a kind of ideology embedded in them. Here we're facing a different kind of much more complex compression, because it's not only about reducing the size of a file to allow for easier circulation, for streaming, and so on. It's about compressing vast areas of cultural memory. And if you think that apparently, for the latest models of large language models such as Chachapiti, it is all the texts available in English online that have been used for this compression. You imagine the massive dimension of this operation that reduces everything to lower dimensional vectors. And through this reduction, it does capture some relations with them, some features, but it also discards many others.
And we don't know, and in many cases, the programmers who actually put these models at work don't even know themselves what parts are kept and what are not, and what's getting lost. And one of the questions is, for example, when it comes to images, is what happens to all those properties that determined the temporal status of those images, the historical context of those images. What happens when billions of images are flattened into vectors and end up in these abstract spaces? What happens of their temporal status? Is it completely erased? Does it disappear? Do all temporalities end up kind of flattened into a sort of floating state? So there's a lot of things that happen there. And so the question is, what kind of compression we're talking about, not compression in itself. I don't know if I answered the question. I think it's a good question. Yes, two questions here and there. Yeah, thank you for the presentation. Actually, I also… Yeah. I was also wondering about the limits of this media archaeological homology, let's say, when you were comparing AI to the archives, because it seems like there is something un-reducible, which you called a black box.
Because, for instance, when people were theorizing on search engines, there were like this huge debate. I remember like in Lev Manovich's books, there was this comparison between imperative search when you can enter like direct, like some sort of like question that will be responded directly. But with the algorithms, the search engine, a little bit like to fine-tune this kind of approach, and you have more smooth answers on what you are like wondering. But with ChatGPT, for instance, we have this new thing that I can answer. I can ask a question and answer, even if I don't know what I'm asking about. So there is some sort of things that are not accessible through archives, because through archives, I cannot like complete that kind of tasks. But with ChatGPT, I can ask something I'm not sure about, something which is not that direct and not imperative, and it still can be like when, for instance, I'm asking about movie, I don't remember the name. I remember really few details, which if I'm going to process this through archive, I cannot do that. But through the use of GPT models, through this black box feature of them, I can accomplish that kind of thing.
Yeah. First of all, I'm not trying to do a kind of media archaeology of AI. I'm trying to position in history latent spaces, so something more specific. And I think that latent spaces, like many other entities, processes that are part of this vast complex field of AI, need to be questioned. And one way of questioning them is by trying to position them in a historical, genealogical, media archaeological perspective. See where they come from, how they came to be constituted. Not take them as kind of inevitable accomplishments of, you know, kind of technological progress, but on the contrary, position them in longer histories of technology, technologies, ideologies, cultural techniques, and so on. And some of the analogies that I presented, of course, are only very, very, very partial. But I think that given the importance that these latent spaces are playing in the processing of cultural objects, of cultural memory, in the transmission of culture, I think that the comparison with libraries and archives is interesting. Also to point out the huge differences. For example, the fact that latent spaces are not meant for retrieval. But, you know, libraries and archives are also institutions that have been historically very, very heavily and ideologically oriented and conceived.
In some cases, libraries were not public, were not open. They were repositories of a knowledge that was only accessible to a certain part of the ruling class and so on. So I think it's a legitimate attempt, as long as it does reveal something about latent spaces and perhaps about libraries themselves. And the comparison I made with perspective also may seem very far-fetched, but at the same time, I think that asking whether latent spaces are the expression of a point of view, I think, is a legitimate question. We've been talking about orientation, but we could also think whether there is a situatedness of latent spaces, where they are the expression, the representation in compressed form of a certain cultural historical position. And I think that is something that perspective also, through Panofsky's famous essay, may help us think about. Boris? Thank you for a great lecture. I guess we all need to see the exhibition absolutely now. Sorry? We absolutely need to see the exhibition now. Thank you for the great lecture. I think this is a very promising genealogy that you present, so maybe excuse a very basic gap-filling question. How would this history of latent space relate to a maybe more basic, classic notion of media having latency?
The media having latency, so like Henry Fox Talbot is taking a photo of people in front of stock exchange, we only get the stock exchange that people are missing because of long exposure times. But that does not prevent the artist later in the future to capitalize on this inherent latency of all media to precisely produce an allegorical form of meaning and say, hey, this is exactly how capitalism abstracts the human body from the general structure and so on. We have the same with time lapse photography and so on. How would your history of latent spaces basically relate to this space for media history but also kind of artistic potentials? Absolutely. I think there's a lot to think about in that direction. There's also a lot to think about in terms of what is the meaning of latent in the expression latent space. Because there's different terms that are being used. One is vector space, one is embedding space. I'm actually privileging latent spaces because I'm interested in thinking about this idea of latency. This idea of latency refers at the same time to what's been eliminated from this compression. When in the technical language this term was coined was to talk about latent variables which were variables that contain certain features while discarding others.
So latency refers both to what has been discarded but also to the almost ontological status of these vectors which potentially contain images that could be visualized or not and that exist in a state of potentiality, in a state of latency. Latency, of course, refers to the radical invisibility, inaccessibility, and the fragility of these spaces. So I think we need to keep all these resonances present. Thank you. Okay, one question over there. Kako? Hello, thank you very much for a great lecture. The way you explained the latent space, it really much reminds me of the black hole, the idea of black hole and some kind of form of accumulation. Form of like a gravity that latent space has, this kind of political gravity that kind of brings everything in one place. And mathematically, I don't know, but we know that there are some kind of conditions that accumulation of the information turns into, like, collapse into the black holes that nothing can escape from it. And this kind of reminds me, can be some kind of like a spaghettification, of like the logic of the accumulation. And also, if you're talking about the point of view, some kind of thing, this console kind of different, if defined by how close you are to the black hole, because if you are close, you're being spaghettified physically somehow.
But if you look at it from distance, and you just are stuck in the horizon, and it's just something, and only things, the speculating now that leaves, it's kind of like from the black hole is radiation. That that can be kind of the shadow you're talking about, for example. Thank you. Yeah, thanks a lot for that. Thank you. Do you want to react to this? Yes, it's an interesting metaphor. We could say in a way that, as generative AI really infiltrates all layers of society today, there is a kind of gravitational force that brings all digital objects existing online towards these latent spaces. The title of Matt Dreierhurst and Holly Hernon's new book is All Media Are Training Data. And what do they mean by that? Is that, today we are more and more in the condition in which whatever media content, because this is what they mean, media content, we produce and we end up putting online, that content is destined at some point to become part of the training data. So faced with this, we can either develop strategies to avoid entering these training sets, but these strategies are becoming more and more difficult to enforce, especially when in the US you have companies such as OpenAI, which now reclaim what they call freedom to learn.
What does freedom to learn mean? Freedom to access everything that's online without any barrier. So we could say that these models act as gravitational forces that pull every single digital object towards them, towards their latent space. Of course, we will also have to see how all these develop. It's not necessarily by incorporating more and more data that this model will develop and improve from their point of view. But anyway, I like this metaphor and I think there's something that can be done with it. Thank you. Maybe, yeah, I will… Is it a short question? Yes, I'll try to make it short. Thank you for the inspiring talk. And the idea of compression. And maybe we should think about whether this is lossless compression, a lossy compression, or just an abstraction into numbers through which we interpolate and create something that looks like an image, but maybe something completely different. Maybe it's just a data visualization. But apart from that, my question is the following. Now we have that technology and everyone can use it via daily or mid-journey and so on. And I think that's a good way to start the journey and so on.
And the internet is flooded with those kinds of images or data. What do we do with it now? Do we need something, a new science that deals with such media, a new method how to deal with it? Do we need something like digital visual culture or something like that? What changes with this technology? Thank you. Thank you. First of all, first part, I think, and in this I follow the work by Leonardo Impet and Fabian Offert, that this is a case of lossy compression. It is not about compressing in order to go back and find exactly everything as it was. It's actually about losing some part of the data in order to create this vector space that can then produce other data. So it's a kind of lossy compression. But it's different from, as I said, JPEG and MP3s. And in terms of what do we need, from the point of view of me as a scholar, let's say, I think it's crucial for image theory, visual culture studies, built Wissenschaft, made in Wissenschaft, to really become more and more familiarized with these issues, these terms, these technical terms, often not easy to understand if we don't have a computer science background, as I don't.
But we need to, we need to integrate this knowledge. Otherwise, we're missing some of the key processes that today rule the entire cultural circulation of images, from their production, storing, sharing, transforming, transmitting, and so on. It's the entire life circle of images that is impacted more and more by this. And we cannot miss that. And we can also not leave it up to computer science to deal with this, because they do it very often with a perspective that is complex, completely apolitical, completely uninterested in both historical aspects and ideological aspects. It's very important to find moments of encounter between disciplines and in this sense, I think. Okay. Yeah, I would like to have a short reaction to basically everything that was, many things that were said today, like a response. And I'm just going to try to continue this project of reverse engineering things, because I remember also that Deleuze-Gautier, at least I think I remember, I haven't looked it up, described fascism as this black hole, from whose gravity you cannot escape anymore. So let's try to go back into the other direction where gravity has less pull. And if you continue to reverse engineer the vector into the other direction, then actually Paul gave me a great idea.
He googled the etymology of the word vector, and he figured out that it means to carry or to convey. You know, it's someone who carries something or conveys something. And he reminded me that, of course, this opens up this whole alternative genealogy of possibly the latent space, which is the idea of the carrier-back theory, which Francis and I also used, for our publication, which is this idea of Ursula Le Guin, that, of course, there's not only this heroic, you know, Elon Musk, go to Mars, kind of technological narrative, but there is also the idea that the carrier-back, which is an alternative version of the vector, is something much more humble, but in a way much more highly developed and at the source of any kind of technology. So having said that, if I was to develop now, a carrier-back theory of the vector, where would that lead me? And I think that's quite interesting, or maybe, maybe interesting, I have no idea. It's a very quick reaction now. But where would I go with that? And I went, of course, through all the different methods that Antonio gave to create different kinds of latent spaces, and I think I would like to add another one, because obviously I tried most of them, or I tried all of them, and there is always this kind of barrier one hits when trying to really retrain a foundational model.
It's not possible. I mean, I'm really curious what Matt is going to come up with tomorrow in retraining public diffusion, but it's a whole effort that requires a lot of infrastructure, et cetera, et cetera. And why is this necessary? Because with all these other methodologies, you don't really get rid of the fundamental architecture, or problem of latent spaces, which is the problem of similarity and homophily. Homophily is this term that Wendy Chan developed, or analyzed, you know, it's a term from social network theory, that in social network things that are close are thought to be similar. And I think this is also how a lot of the clusters work within latent spaces. They are arranged by similarity, or homophily. And interestingly enough, this term was developed, as Wendy figured out, in a sort of urban theory of segregated neighborhoods. Homophily was a reaction that some people thought that people, residents of segregated neighborhoods don't like them, they prefer similar people that are similar to them. And this is a structuring principle, I think, of latent spaces as well. It's a kind of segregation of these latent spaces into similar neighborhoods. So in that sense, I think one of the consequences would be to think about how to desegregate latent spaces.
How would one do that? And I think this is a very simple methodology, because if I think of, you know, all the missing infrastructure of doing this in the latent space, I start, I end up asking myself, why don't we do it in real space? Because all these, you know, neighborhoods with dissimilarities kind of exist, right, in real life. They are under massive attack by the forces we are talking about who want to basically segregate them again, or gentrify, or make them similar, et cetera, et cetera. So I think if we want to think about how to create a dynamic space, a different kind of latent, then one has to think about preserving or creating the dissimilar spaces that we already have in real life, you know, because otherwise, we go this huge detour through the latent space to make some spaces in real life, whereas I could just go, which is something which I think very often nowadays in dealing with AI, I could just go and talk to my neighbor, right, instead of doing this whole detour through the latent space. So this is one thing I would like to add to the list of all the, you know, possibilities to intervene into latent space to start with in real life space.
And having said that, thank you, everyone, all the participants, all the people that contributed in one form or another, be it the technicians, the people that organized, Francis, who basically organized the whole infrastructure, Paul, et cetera. We will now end this session. We have prepared some snacks, et cetera, and drinks in the other space, which someone, if we don't get lost, will lead you to. It's not a latent, it's very real. And we will continue at 12 p.m. tomorrow. Thank you. Thanks a lot. Thank you.